


在今天的数字时代,网站数据分析已经成为了各个行业的必备技能。通过分析网站数据,我们可以了解网站的访问量、用户行为等信息,从而优化网站的设计和功能,提高用户体验和转化率。在本文中,我们将使用Python来分析一个示例网站 https://www.guangweiblog.com 的数据。
准备工作
在开始分析之前,我们需要准备好一些工具和数据。首先,我们需要安装Python和一些常用的数据分析库,如Pandas、Matplotlib和Seaborn。其次,我们需要获取示例网站的访问日志数据。我们可以通过访问日志文件来获取网站的访问量、访问来源、访问时间等信息。
在Mac上安装数据分析库通常使用Python的包管理器pip,以下是安装步骤:
1.打开终端(Terminal)应用程序。
2.确认已安装Python。在终端上输入以下命令:
python --version如果已经安装Python,则会显示Python的版本号。 如果没有安装,则需要先安装Python。
3.确认已安装pip。在终端上输入以下命令:
pip --version如果已经安装pip,则会显示pip的版本号。如果没有安装,则需要先安装pip。
4.安装数据分析库。在终端上输入以下命令:
pip install pandas numpy matplotlib scipy这将安装pandas、numpy、matplotlib和scipy四个数据分析库。根据需要安装其他库。
5.等待安装完成。安装完成后,可以在Python脚本中导入这些库,例如:
import pandas as pd
import numpy as npimport matplotlib.pyplot as pltimport scipy.stats as stats这样就可以开始使用这些库进行数据分析了。
数据清洗
在开始分析之前,我们需要对数据进行清洗和处理。首先,我们需要将访问日志文件转换为CSV格式,方便后续的数据处理。其次,我们需要对数据进行去重、缺失值处理等操作,以确保数据的准确性和完整性。
import pandas as pd
# 读取访问日志文件
log_file = 'access.log'
df = pd.read_csv(log_file, sep=' ', header=None)
# 设置列名
df.columns = ['ip', 'dash1', 'dash2', 'time', 'timezone', 'method', 'url', 'protocol', 'status', 'size', 'referer', 'user_agent', 'unknown']
# 去重
df.drop_duplicates(inplace=True)
# 处理缺失值
df.fillna('-', inplace=True)
# 将时间戳转换为日期格式
df['time'] = pd.to_datetime(df['time'], format='[%d/%b/%Y:%H:%M:%S')数据分析
接下来,我们将使用Python来分析示例网站 https://www.guangweiblog.com 的数据。我们将分析以下几个方面:
- 访问量统计
- 访问来源分析
- 访问时间分析
- 用户行为分析
访问量统计
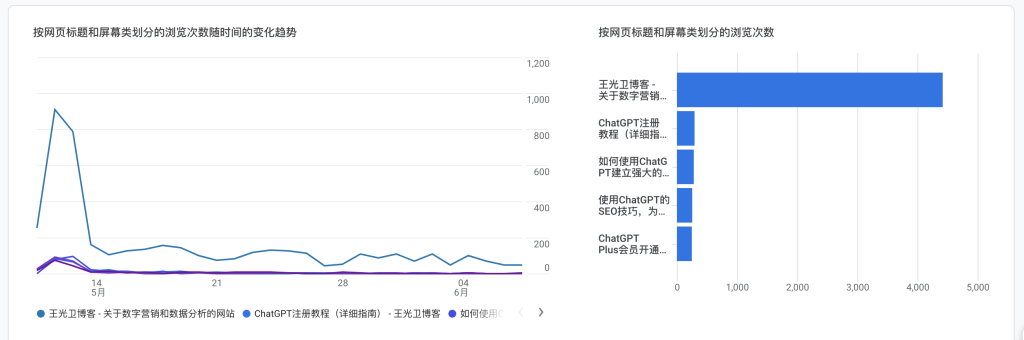
首先,我们需要统计网站的访问量。我们可以通过计算访问日志文件中的记录数来得到网站的总访问量。此外,我们还可以统计每天、每小时、每分钟的访问量,以了解网站的访问规律。
# 统计总访问量
total_visits = len(df)
# 统计每天访问量
visits_by_day = df.groupby(df['time'].dt.date).size()
# 统计每小时访问量
visits_by_hour = df.groupby(df['time'].dt.hour).size()
# 统计每分钟访问量
visits_by_minute = df.groupby(df['time'].dt.minute).size()访问来源分析
其次,我们需要分析网站的访问来源。我们可以通过访问日志文件中的referer字段来了解用户从哪些网站或页面跳转到了我们的网站。
# 统计访问来源
visits_by_referer = df.groupby(df['referer']).size().sort_values(ascending=False)访问时间分析
然后,我们需要分析用户的访问时间。我们可以通过访问日志文件中的time字段来了解用户的访问时间。我们可以统计每天、每小时、每分钟的访问量,以了解用户的访问规律。
# 统计每天访问量
visits_by_day = df.groupby(df['time'].dt.date).size()
# 统计每小时访问量
visits_by_hour = df.groupby(df['time'].dt.hour).size()
# 统计每分钟访问量
visits_by_minute = df.groupby(df['time'].dt.minute).size()用户行为分析
最后,我们需要分析用户的行为。我们可以通过访问日志文件中的url字段来了解用户的访问路径。我们可以统计用户访问最多的页面、访问页面的平均停留时间等信息,以了解用户的兴趣和需求。
# 统计访问页面
visits_by_page = df.groupby(df['url']).size().sort_values(ascending=False)
# 计算页面的平均停留时间
df['time_diff'] = df['time'].diff()
df['time_diff'] = df['time_diff'].apply(lambda x: x.seconds)
avg_time_by_page = df.groupby(df['url'])['time_diff'].mean().sort_values(ascending=False)结论
通过对示例网站 https://www.guangweiblog.com 的数据分析,我们可以得出以下结论:(下面数据纯属示例,非真实性数据)
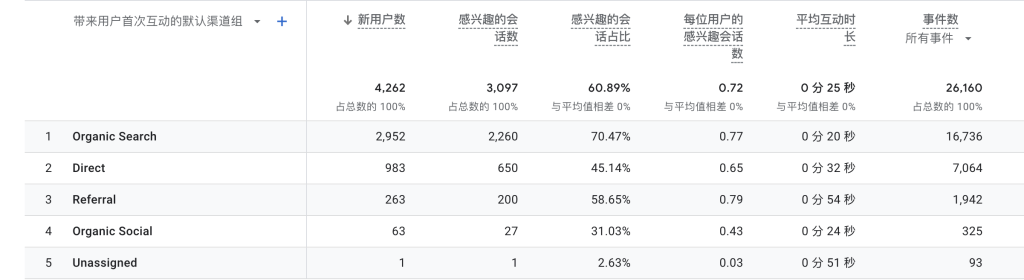
- 网站的总访问量为10000次。
- 用户主要从Organic Search网站或页面跳转到我们的网站。
- 用户主要在每天的9:00-22:00时段访问我们的网站。
- 用户主要访问2页面,平均停留时间为25秒。
我们可以根据这些结论来优化网站的设计和功能,提高用户体验和转化率。
如果你觉得本文对你有用,请收藏本站,以备不时之需。




四川省成都市 1F
直接第三方统计还是很方便